Сама по себе генерация превьюшек — штука забавная, но в большинстве случаев бессмысленная, т.к. контент обычно представляет из себя черные буквы на белом фоне и все превьюшки выглядят одинаково. Усугубляется всё тем, что для работы встроенного в DSpace механизма генерации превью для PDF требуются внешние инструменты.
В среде GNU/Linux всё достаточно просто, описание доступно здесь. Вообще, очень хороший ресурс по Dspace/Ubuntu. Так же там есть важное упоминание о фильтре Branded Preview JPEG, я его отключил вовсе. Связано это с тем, что работает он только для битстримов изображений, а у нас основной контент — application/pdf.
И так, для того чтобы в DSpace на Windows заработали превьюшки, нам понадобится два дополнительных инструмента — GhostScript и ImageMagic. Первый я качал тут, версию Ghostscript 9.16 for Windows (64 bit) GPL Release. разрядность системы каждый выберет подходящую, но если OS и Java имеют 64 bit разрятность, то и GhostScript с ImageMagic можно брать на 64 bit. Последний к слову берётся тут. В самом низу страницы есть сборки под Windows, я использовал ImageMagick-6.9.2-3-portable-Q16-x64.zip. Люблю статические сборки — юниксвей 🙂
Далее, необходимо создать директории C:\RUNTIME\GS и C:\RUNTIME\IMAGEMAGIC, стилистику своих установок я пытаюсь сохранять, но в принципе с путями каждый волен делать то, что удобно в каждом конкретном случае. Ghostscript я установил в C:\RUNTIME\GS (прямо в этоу папку, а не в ./gs916), а ImageMagic извлёк в C:\RUNTIME\IMAGEMAGIC.
Далее необходима правка dspace.cfg:
# Media/Format Filters help to full-text index content or
# perform automated format conversions
#Names of the enabled MediaFilter or FormatFilter plugins
filter.plugins = PDF Text Extractor, HTML Text Extractor, \
PowerPoint Text Extractor, \
Word Text Extractor, ImageMagick Image Thumbnail, ImageMagick PDF Thumbnail
#filter.plugins = PDF Text Extractor, HTML Text Extractor, \
# PowerPoint Text Extractor, \
# Word Text Extractor, JPEG Thumbnail
# [To enable Branded Preview]: uncomment and insert the following into the plugin list
# Branded Preview JPEG, \
# [To enable ImageMagick Thumbnail]:
# remove "JPEG Thumbnail" from the plugin list
# uncomment and insert the following line into the plugin list
# ImageMagick Image Thumbnail, ImageMagick PDF Thumbnail, \
#Assign 'human-understandable' names to each filter
plugin.named.org.dspace.app.mediafilter.FormatFilter = \
org.dspace.app.mediafilter.PDFFilter = PDF Text Extractor, \
org.dspace.app.mediafilter.HTMLFilter = HTML Text Extractor, \
org.dspace.app.mediafilter.WordFilter = Word Text Extractor, \
org.dspace.app.mediafilter.PowerPointFilter = PowerPoint Text Extractor, \
org.dspace.app.mediafilter.ImageMagickImageThumbnailFilter = ImageMagick Image Thumbnail, \
org.dspace.app.mediafilter.ImageMagickPdfThumbnailFilter = ImageMagick PDF Thumbnail
#plugin.named.org.dspace.app.mediafilter.FormatFilter = \
# org.dspace.app.mediafilter.PDFFilter = PDF Text Extractor, \
# org.dspace.app.mediafilter.HTMLFilter = HTML Text Extractor, \
# org.dspace.app.mediafilter.WordFilter = Word Text Extractor, \
# org.dspace.app.mediafilter.PowerPointFilter = PowerPoint Text Extractor, \
# org.dspace.app.mediafilter.JPEGFilter = JPEG Thumbnail, \
# org.dspace.app.mediafilter.BrandedPreviewJPEGFilter = Branded Preview JPEG, \
# org.dspace.app.mediafilter.ImageMagickImageThumbnailFilter = ImageMagick Image Thumbnail, \
# org.dspace.app.mediafilter.ImageMagickPdfThumbnailFilter = ImageMagick PDF Thumbnail
#Configure each filter's input format(s)
filter.org.dspace.app.mediafilter.PDFFilter.inputFormats = Adobe PDF
filter.org.dspace.app.mediafilter.HTMLFilter.inputFormats = HTML, Text
filter.org.dspace.app.mediafilter.WordFilter.inputFormats = Microsoft Word
filter.org.dspace.app.mediafilter.PowerPointFilter.inputFormats = Microsoft Powerpoint, Microsoft Powerpoint XML
#filter.org.dspace.app.mediafilter.BrandedPreviewJPEGFilter.inputFormats = BMP, GIF, JPEG, image/png
filter.org.dspace.app.mediafilter.ImageMagickImageThumbnailFilter.inputFormats = BMP, GIF, image/png, JPG, TIFF, JPEG, JPEG 2000
filter.org.dspace.app.mediafilter.ImageMagickPdfThumbnailFilter.inputFormats = Adobe PDF
#filter.org.dspace.app.mediafilter.PDFFilter.inputFormats = Adobe PDF
#filter.org.dspace.app.mediafilter.HTMLFilter.inputFormats = HTML, Text
#filter.org.dspace.app.mediafilter.WordFilter.inputFormats = Microsoft Word
#filter.org.dspace.app.mediafilter.PowerPointFilter.inputFormats = Microsoft Powerpoint, Microsoft Powerpoint XML
#filter.org.dspace.app.mediafilter.JPEGFilter.inputFormats = BMP, GIF, JPEG, image/png
#filter.org.dspace.app.mediafilter.BrandedPreviewJPEGFilter.inputFormats = BMP, GIF, JPEG, image/png
#filter.org.dspace.app.mediafilter.ImageMagickImageThumbnailFilter.inputFormats = BMP, GIF, image/png, JPG, TIFF, JPEG, JPEG 2000
#filter.org.dspace.app.mediafilter.ImageMagickPdfThumbnailFilter.inputFormats = Adobe PDF
#Publicly accessible thumbnails of restricted content.
#List the MediaFilter name's that would get publicly accessible permissions
#Any media filters not listed will instead inherit the permissions of the parent bitstream
#filter.org.dspace.app.mediafilter.publicPermission = JPEGFilter, XPDF2Thumbnail
filter.org.dspace.app.mediafilter.publicPermission = ImageMagick Image Thumbnail, ImageMagick PDF Thumbnail
#Custom settings for PDFFilter
# If true, all PDF extractions are written to temp files as they are indexed...this
# is slower, but helps ensure that PDFBox software DSpace uses doesn't eat up
# all your memory
#pdffilter.largepdfs = true
# If true, PDFs which still result in an Out of Memory error from PDFBox
# are skipped over...these problematic PDFs will never be indexed until
# memory usage can be decreased in the PDFBox software
#pdffilter.skiponmemoryexception = true
# Custom settigns for ImageMagick Thumbnail Filters
# ImageMagick and GhostScript must be installed on the server, set the path to ImageMagick and GhostScript executable
# http://www.imagemagick.org/
# http://www.ghostscript.com/
# Note: thumbnail.maxwidth and thumbnail.maxheight are used to set Thumbnail dimensions
# org.dspace.app.mediafilter.ImageMagickThumbnailFilter.ProcessStarter = /usr/bin
org.dspace.app.mediafilter.ImageMagickThumbnailFilter.ProcessStarter = C:/RUNTIME/IMAGEMAGIC
# bitstreams generated by this process will contain the following description and may be overwritten
# org.dspace.app.mediafilter.ImageMagickThumbnailFilter.bitstreamDescription = IM Thumbnail
#
# bitstream descriptions that do not conform to the following regular expression will not be overwritten
# org.dspace.app.mediafilter.ImageMagickThumbnailFilter.replaceRegex = ^Generated Thumbnail$
#
# While PDFs may contain transparent spaces, JPEG cannot. As DSpace use JPEG
# for the generated thumbnails, PDF containing transparent spaces may lead
# to problems. To solve this the exported PDF page is flatten before it is
# resized and stored as JPEG. You can switch this behavior off by setting the
# next property false, if necessary for any reasons.
# org.dspace.app.mediafilter.ImageMagickThumbnailFilter.flatten = true
А теперь по пунктам:
1. Убираем из filter.plugins ненужные плагины генерации превьюшек JPEG’ов, добавляем плагины ImageMagic:
PowerPoint Text Extractor, \
Word Text Extractor, ImageMagick Image Thumbnail, ImageMagick PDF Thumbnail
2. Правим список человекочитаемых «ярлыков» используемых плагинов. В принципе можно и не править, а оставить как есть:
org.dspace.app.mediafilter.PDFFilter = PDF Text Extractor, \
org.dspace.app.mediafilter.HTMLFilter = HTML Text Extractor, \
org.dspace.app.mediafilter.WordFilter = Word Text Extractor, \
org.dspace.app.mediafilter.PowerPointFilter = PowerPoint Text Extractor, \
org.dspace.app.mediafilter.ImageMagickImageThumbnailFilter = ImageMagick Image Thumbnail, \
org.dspace.app.mediafilter.ImageMagickPdfThumbnailFilter = ImageMagick PDF Thumbnail
3. Назначаем какому плагину с каким типом файлов работать:
filter.org.dspace.app.mediafilter.HTMLFilter.inputFormats = HTML, Text
filter.org.dspace.app.mediafilter.WordFilter.inputFormats = Microsoft Word
filter.org.dspace.app.mediafilter.PowerPointFilter.inputFormats = Microsoft Powerpoint, Microsoft Powerpoint XML
#filter.org.dspace.app.mediafilter.BrandedPreviewJPEGFilter.inputFormats = BMP, GIF, JPEG, image/png
filter.org.dspace.app.mediafilter.ImageMagickImageThumbnailFilter.inputFormats = BMP, GIF, image/png, JPG, TIFF, JPEG, JPEG 2000
filter.org.dspace.app.mediafilter.ImageMagickPdfThumbnailFilter.inputFormats = Adobe PDF
4. Задаём плагины превьюшек (тут важно отметить что и превьюшки генерить и тексты извлекать можно еще и по средствам XPDF и иногда он покруче будет чем PDFBOX):
5. Задаём где лежит ImageMagic:
Вот в общем и всё. Я добавлял пути до бинариков GS/ImageMagic в Path, но как оказалось это не нужно.
Далее необходима небольшая правка в разделе DSPACE UI:
# whether to display thumbnails on browse and search results pages (1.2+)
# If you have customised the Browse columnlist, then you must also
# include a 'thumbnail' column in your configuration (1.5+)
# (This configuration is not used by XMLUI. To show thumbnails in the
# XMLUI, you just need to create a theme which displays them)
webui.browse.thumbnail.show = false
# max dimensions of the browse/search thumbs. Must be <= thumbnail.maxwidth
# and thumbnail.maxheight. Only need to be set if required to be smaller than
# dimension of thumbnails generated by mediafilter (1.2+)
#webui.browse.thumbnail.maxheight = 80
#webui.browse.thumbnail.maxwidth = 80
# whether to display the thumb against each bitstream (1.2+)
# (This configuration is not used by XMLUI. To show thumbnails in the
# XMLUI, you just need to create a theme which displays them)
webui.item.thumbnail.show = true
# where should clicking on a thumbnail from browse/search take the user
# Only values currently supported are "item" and "bitstream"
#webui.browse.thumbnail.linkbehaviour = item
# maximum width and height of generated thumbnails
thumbnail.maxwidth = 300
thumbnail.maxheight = 300
# Blur before scaling. A little blur before scaling does wonders for keeping
# moire in check.
thumbnail.blurring = true
# High quality scaling option. Setting to true can dramatically increase
# image quality, but it takes longer to create thumbnails.
thumbnail.hqscaling = true
#### Settings for Item Preview ####
webui.preview.enabled = false
# max dimensions of the preview image
webui.preview.maxwidth = 600
webui.preview.maxheight = 600
# Blur before scaling. A little blur before scaling does wonders for keeping
# moire in check.
webui.preview.blurring = true
# High quality scaling option. Setting to true can dramatically increase
# image quality, but it will take much longer to create previews.
webui.preview.hqscaling = true
# the brand text
webui.preview.brand = ИМЯРЕК
# an abbreviated form of the above text, this will be used
# when the preview image cannot fit the normal text
webui.preview.brand.abbrev = URAIC
# the height of the brand
webui.preview.brand.height = 20
# font settings for the brand text
webui.preview.brand.font = SansSerif
webui.preview.brand.fontpoint = 12
#webui.preview.dc = rights
Вот весь «кусок» для понимания того что там можно настроить.
А вот то, что настраивалось на нашем сервере:
thumbnail.maxwidth = 300
thumbnail.maxheight = 300
Т.е. показывать превью только на странице ITEM’а и сделать его вписываемым в квадрат 300х300 пикселов.
От больших Branded Preview отказались т.к. в них не было найдено какого-то смысла и работают они к сожалению только с картинками, но не с PDF. Предпросмотр в списке «по заглавию» тоже решили не использовать — картинки мелкие, смысла не несут, а вот в описании документа всё получилось достаточно прилично:
Дореволюционная газета:
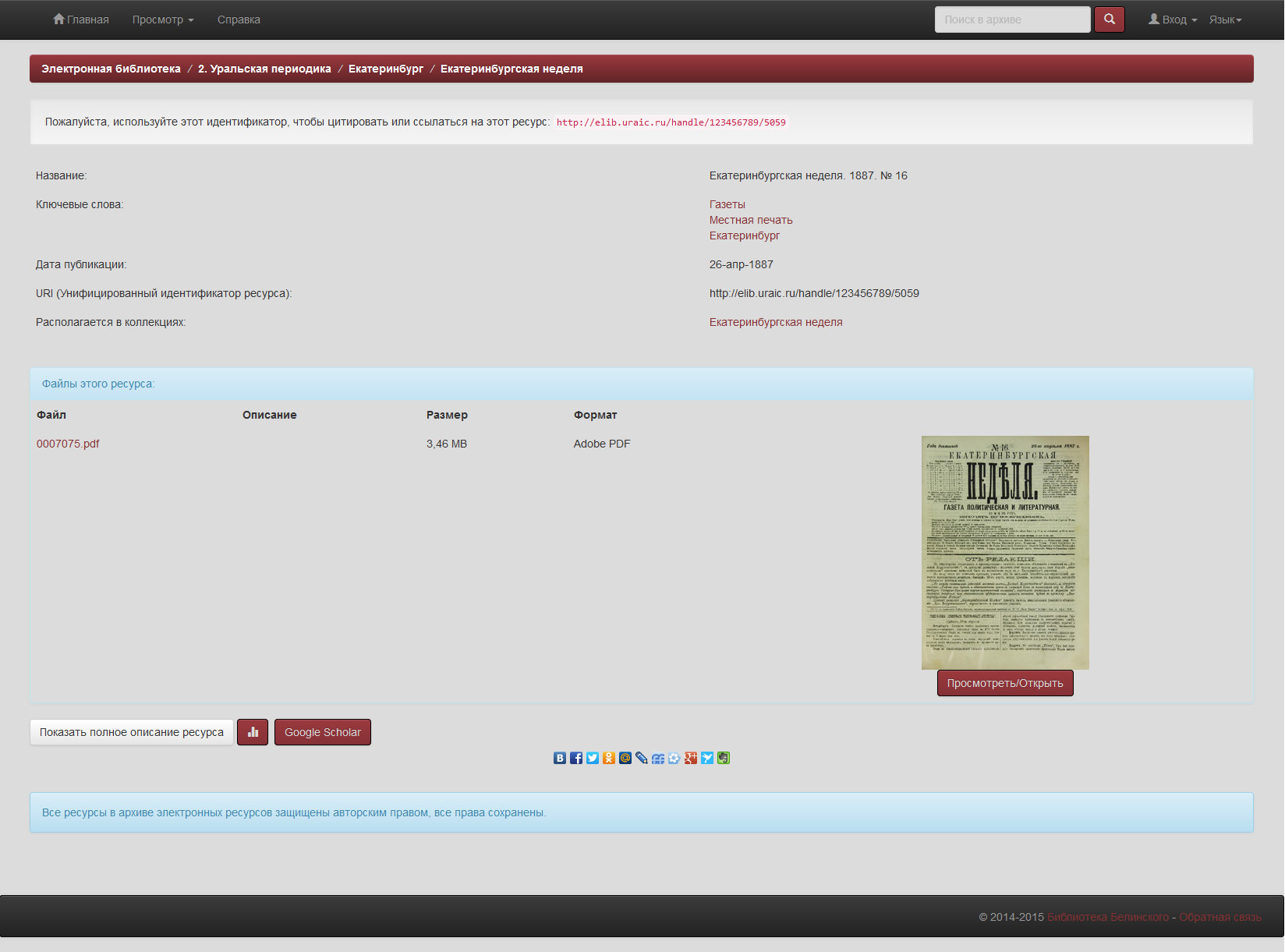
Современная газета:
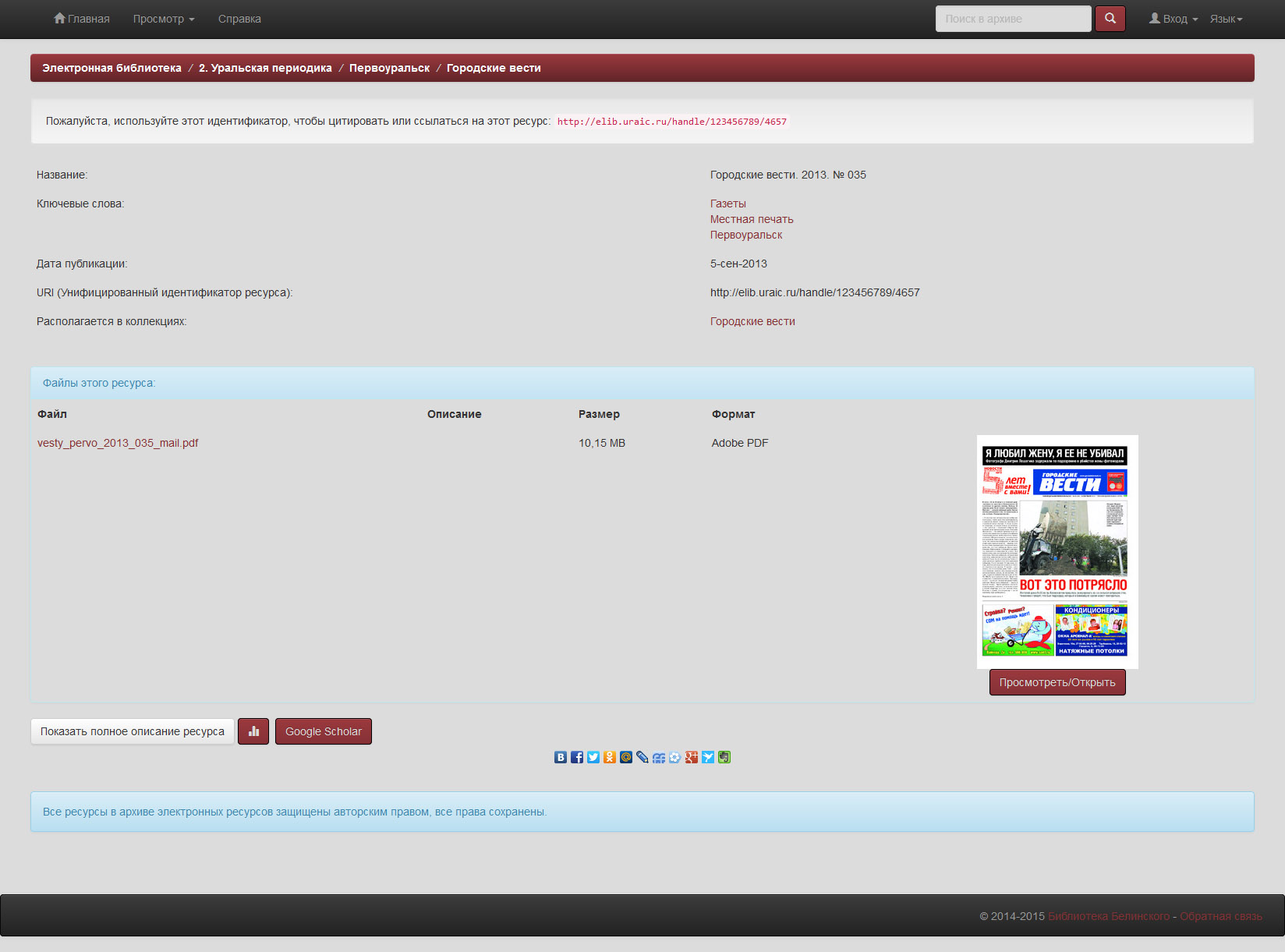
Афиша:
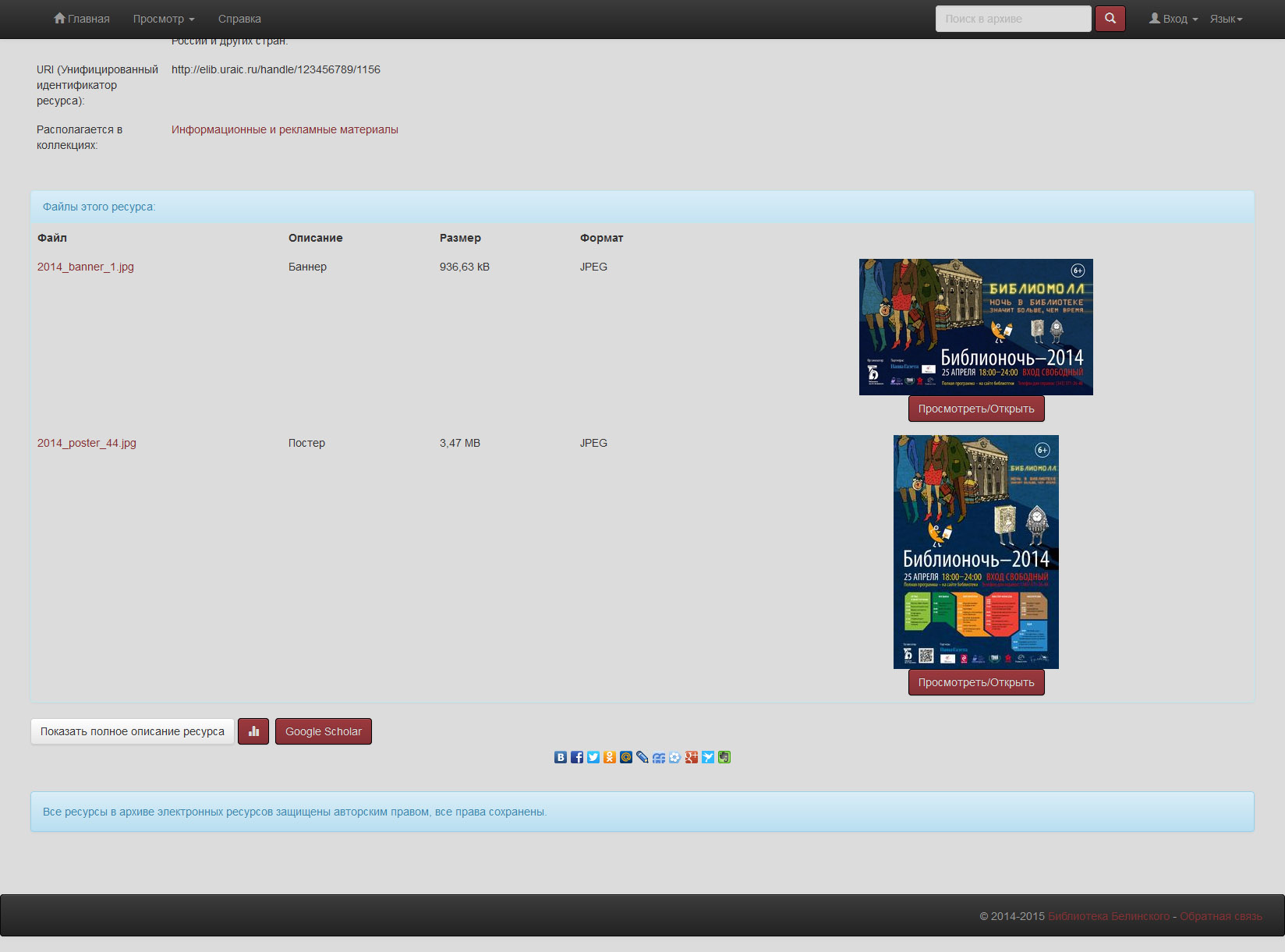
Добавить ко всему этому хочется лишь три момента:
1. Стандартный фильтр JPEG Thumbnail не справлялся со многими нашими афишами. Слишком большие или CMYK палитра или ещё что-то, а ImageMagic обработал всё.
2. ImageMagic не смог обработать буквально несколько штук PDF файлов, оказалось что сами файлы битые — дополнительная проверка. PDFBOX, кстати, просто извлекал из них пустой текстовый файл.
3. Массив из 12 тысяч файлов обрабатывался около 12 часов. Было загружено одно ядро (Xeon X5650 кажется) и использовано 200-300 мегабайт оперативной памяти.
Вживую посмотреть на то как это работает, можно посмотреть на сайте Электронной библиотеки СОУНБ им. В. Г. Белинского.
Добрый день, сделали все как у вас написано, но результата нет никакого. Потом как выяснилось не только превьюшки не показывают, но и логотипы не хотят грузиться, страница бесконечно грузиться пытаясь загрузить логотип но так и не может. Может у вас есть мысли в чем может быть дело? Заранее благодарны.
1. Что за ОС? Что за версия dspace/ghostscript/imagemagic?
2. Покажите конфиги.
3. Когда делаете команду dspace filter-media в терминале видно извлечение jpeg’ов?
jpeg’и создались, но не могут загрузиться как и логотипы, крутит загрузку страницы до бесконечности. Если прервать обновление страницы, то видно что в нужном месте картинка — но она не показывается, вместо нее надпись лого — вместо логотипа и эскиз — вместо превьюшек.
Большое спасибо, вопрос отпал))
Добавлю, что превьюшки создаются только после запуска скрипта media-filter
Его можно запустить вручную, например:
$ /dspace/bin/dspace filter-media -v -i 123456789/1425, где
-v — показывать подробности обработки файлов, -i — запуск для битсритов конкретного handle
или группы материалов:
$ /dspace/bin/dspace filter-media -v -f -m 1000 -p «ImageMagick Image Thumbnail»,
где -f — принудительно запустить для всех битстримов, -m — количество одновременно обрабатываемых материалов, — p — название используемого плагина
Или прописать в cron (в windows — планировщик задач)
Не вижу смысла делать превью pdf-файлов, только изображений.
Иногда речь идёт о книгах с обложками, газетах, «ярких» журналах. Иногда нужно банально показать пользователю что есть полноцвет и бинаризованная версия — http://elar.urfu.ru/handle/10995/37770
Когда начали обрабатывать «мемориальные» фонды, столкнулись с тем что старшее полклдение просто не понимает куда нажимать… а картинка — хорошая подсказка. А в этом архиве в силц специфики материалов превьюшки есть у всех документов — http://elib.uraic.ru/
Но должен еще раз отдельно отметить что сабж даже для JPEG’ов превьюшки генерит с меньшим количеством осечек, чем стандартный инструмент!
Можно ли заставить автоматом делать превью после обуликования материалов без запуска скрипта?
На сколько я знаю, нет.