В рамках конференции Open Repositories 2019 был представлен сервис CORE Discovery. Данный сервис призван решить задачу предоставления доступа к полным текстам научных статей открытого доступа в один клик [в идеале, прим. авт.]. Сервис доступен как в виде расширения для браузера, так и в виде расширения для репозитория, содержащего только метаданные научной статьи. В CORE отмечают большой интерес со стороны сообщества к данному сервису. Одним из представителей сообщества, был автор данного текста. Оригинальный текст в CORE Blog на английском языке доступен по ссылке, ниже будет русскоязычный, исправленный и дополненный вариант.
Как только, интеграция плагина CORE Discovery будет завершена, пользователь, на странице репозитория увидит следующие:
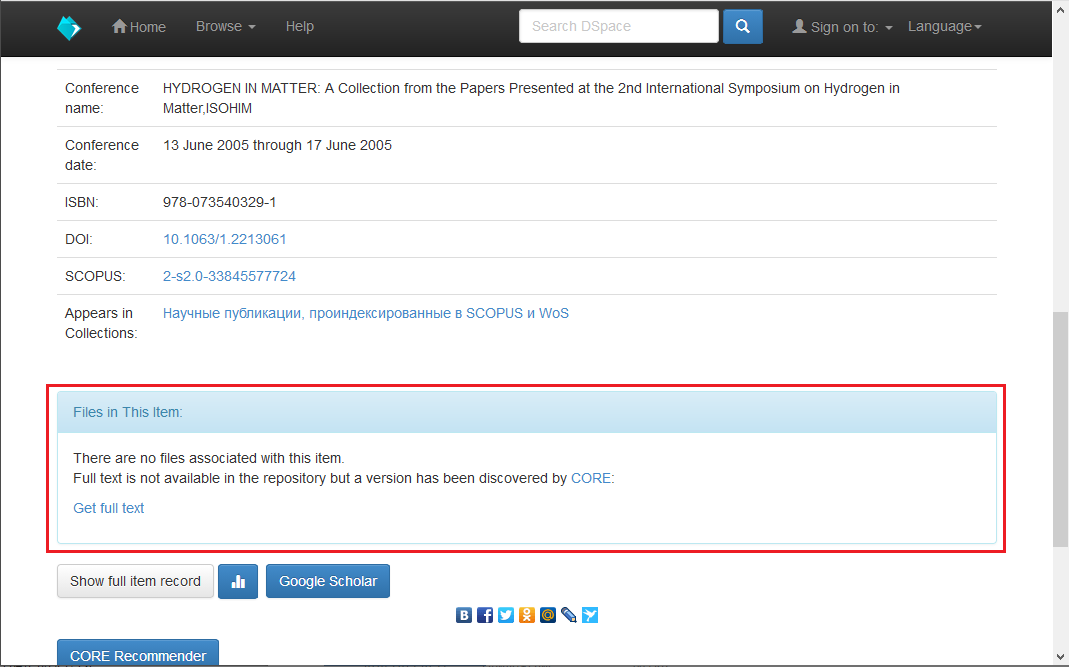
Или, в случае выбора русского языка:
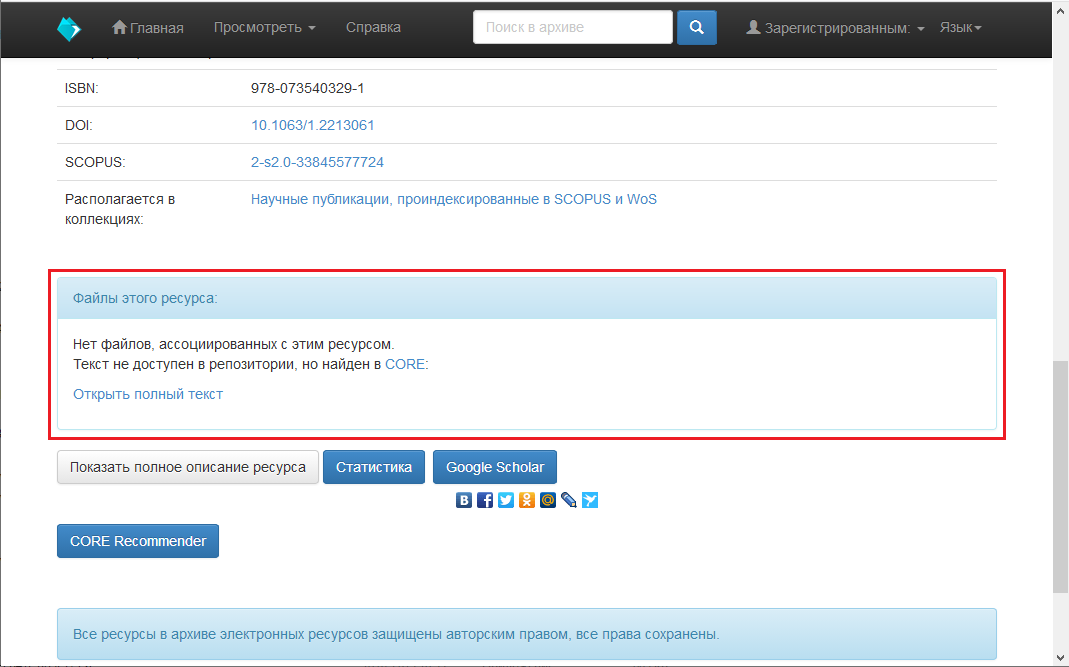
Руководство, данное ниже, описывает процесс интеграции плагина CORE Discovery в DSpace на примере репозитория Российского государственного профессионально-педагогического университета. Данный репозиторий основан на DSpace версии 5.10 (JSPUI).
Следуя документации на плагин, пользователь сначала должен получить уникальный идентификатор для репозитория (это не repository ID агрегатора CORE!). Это можно сделать либо через CORE Dashboard, либо, в случае отсутствия доступа к Dashboard, запросить идентификатор по почте со страницы контактов CORE Team. Данный момент сейчас не совсем прозрачен, но он лишний раз позволяет убедиться в том, что с «той стороны» тоже живые люди, задать какие-то вопросы, поделиться мнением.
После получения идентификатора репозитория необходимо добавить в соответствующие файлы два фрагмента кода.
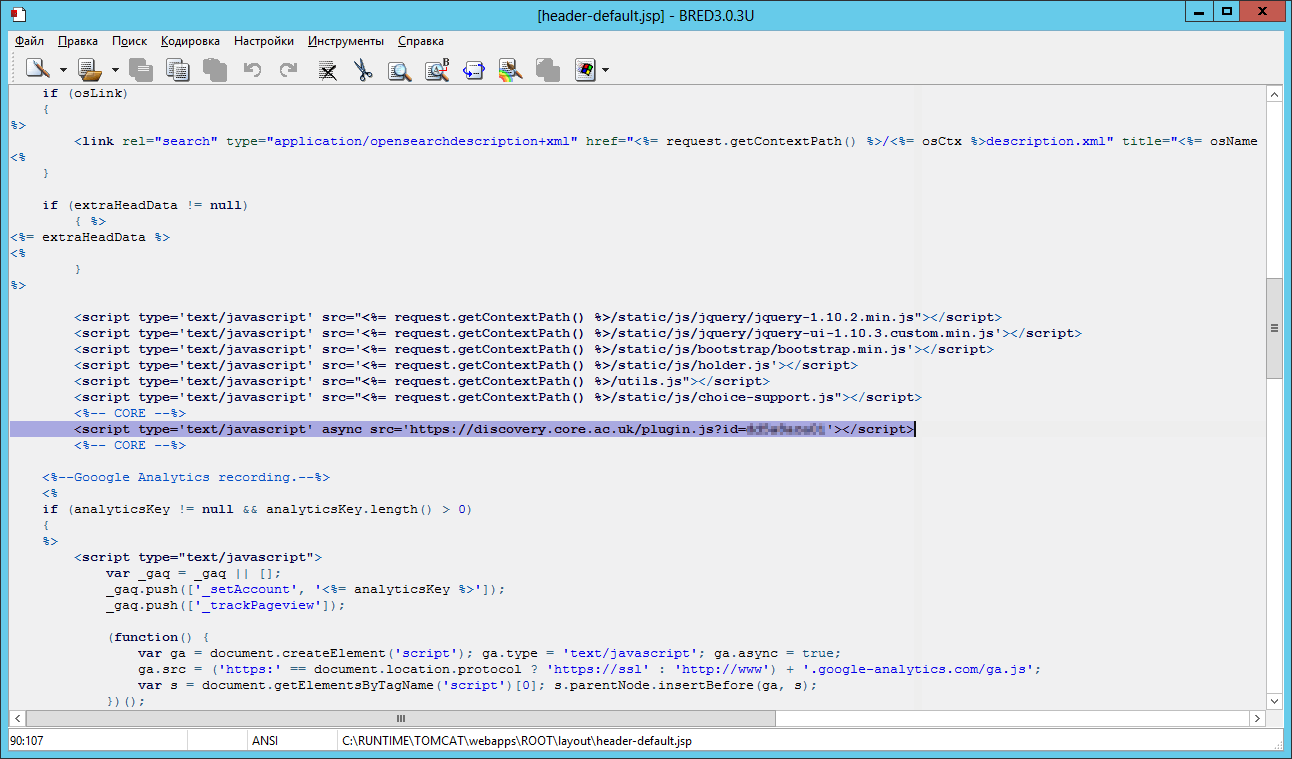
Первый фрагмент — импорт javascript плагина. Для его реализации необходимо добавить код вида:
в заголовок каждой страницы. Естественно, «xxxxxxxxxx» нужно заменить на полученный ID репозитория. В случае с JSPUI для этого необходимо изменить файл header-default.jsp так, как показано на рисунке ниже. Т.е. добавить код со своим ID перед кодом Google Analytics. Обычно, файл заголовка находится по пути /tomcat/webapps/jspui/layout/header-default.jsp
Второй фрагмент кода указывает место на странице, где будет отображаться результат работы плагина. Сам код выглядит так:
и изначально я предлагал модифицировать страницу отображения записи — display-item.jsp, которая обычно расположена по пути /tomcat/webapps/jspui/display-item.jsp, так, как это показано на рисунке ниже.
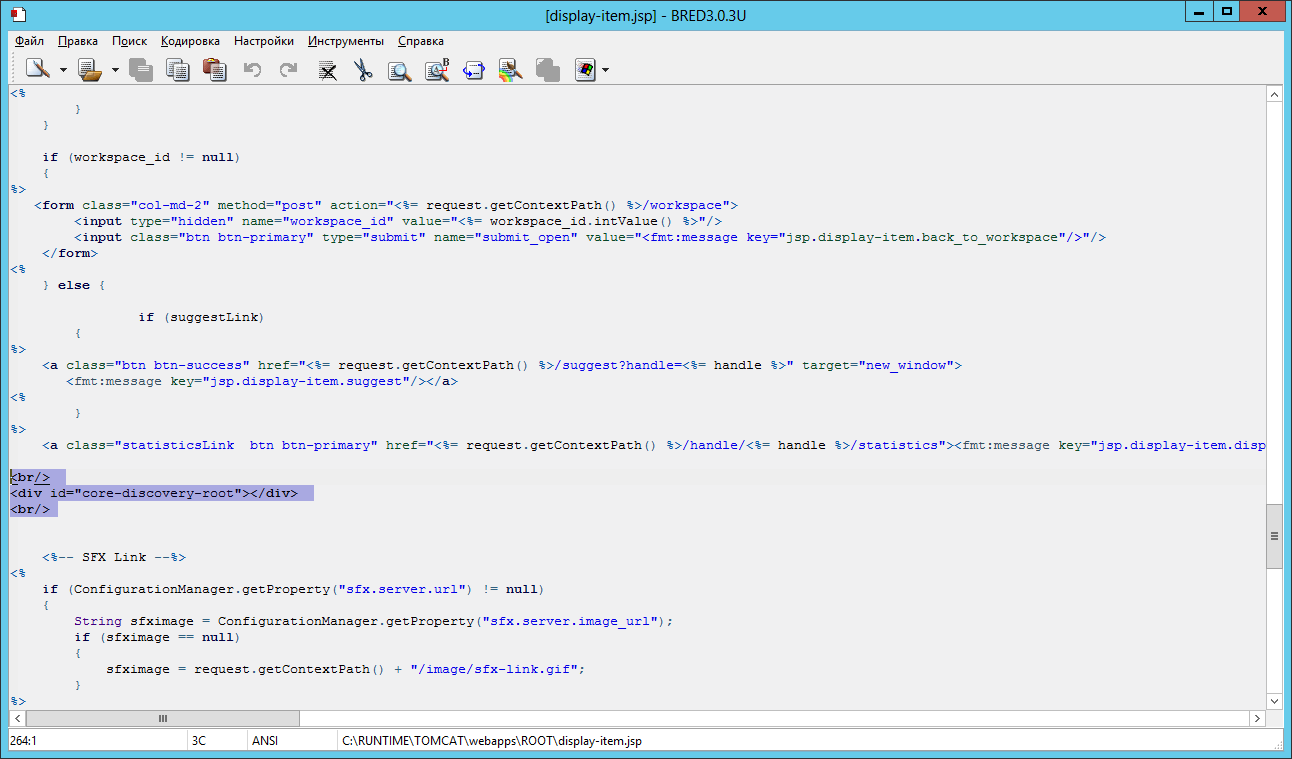
Но такой способ несколько изменяет внешний вид страницы, а так же труднее поддаётся локализации, поэтому, совместно с командой CORE был реализован альтернативный вариант. Со стороны CORE была реализована локализация, как минимум на Английский, Русский, Белорусский и Украинский языки. Для указания языка необходимо использовать двухбуквенные ISO 639-1 коды en, ru, by, uk. Да, я тоже видел что по ссылке написано be, но на данный момент плагин понимает by.
Соответственно, если мы хотим получить интернационализацию и не ломать стандартную раскладку элементов на странице, мы должны…. изменить файл перевода:
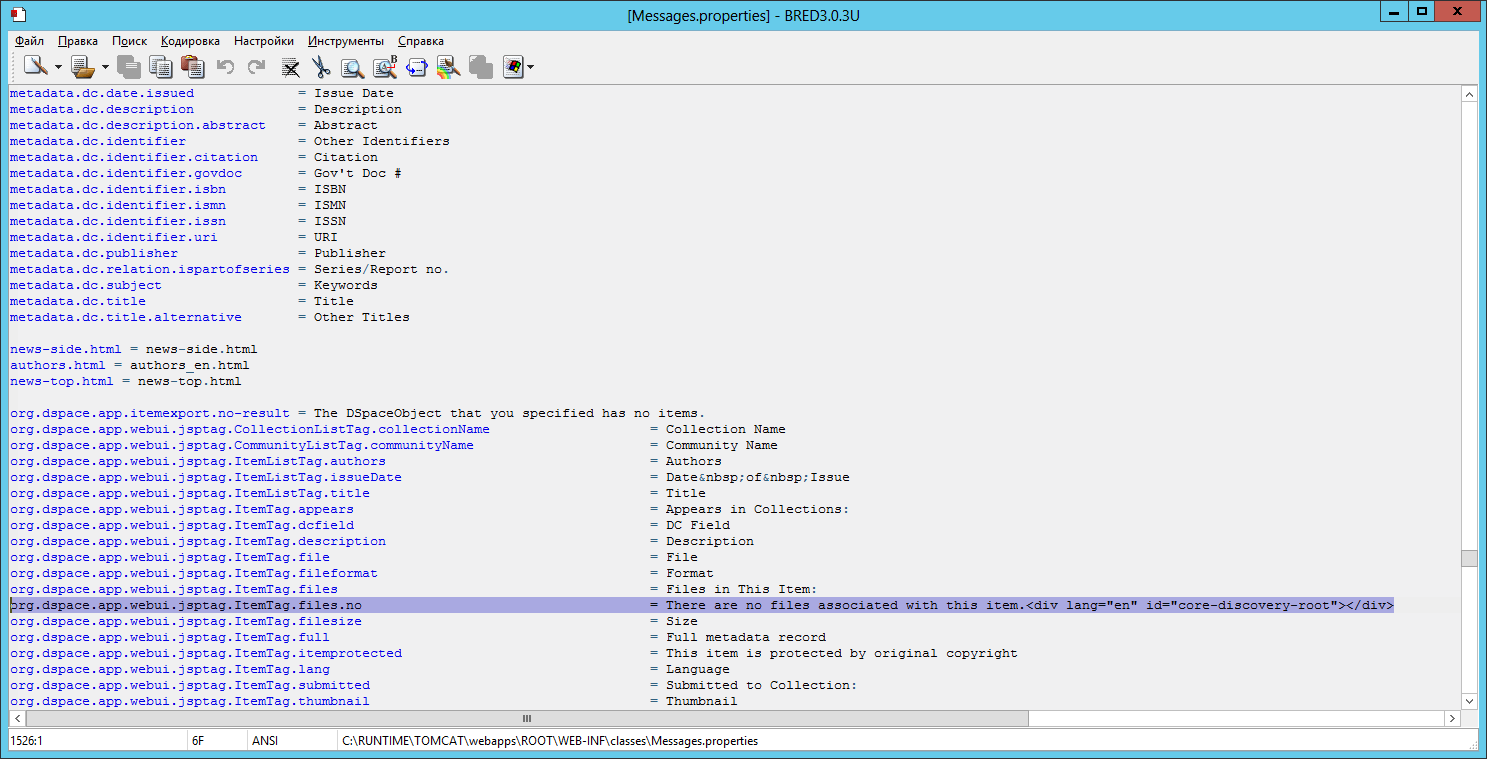
Код фрагмента, указывающего плагину место для вывода результата, соответственно приобретает вид:
Аналогичные правки с точностью до кода языка можно сделать и для других файлов локализации, т.е. для Messages_ru.properties и пр.
Когда код добавлен, необходимо убедиться в верном маппировании DOI. К сожалению, в значительном количестве репозиториев стандартные средства DSpace по реализации маппирования полей, а так же добавления тех полей, которые отсутствуют в стандартных реестрах метаданных (например, такие поля, как DOI), не используются совсем. Если при просмотре исходного кода в заголовке страницы с документом, в метаданных которого присутствует DOI, вы видите подобную картину:
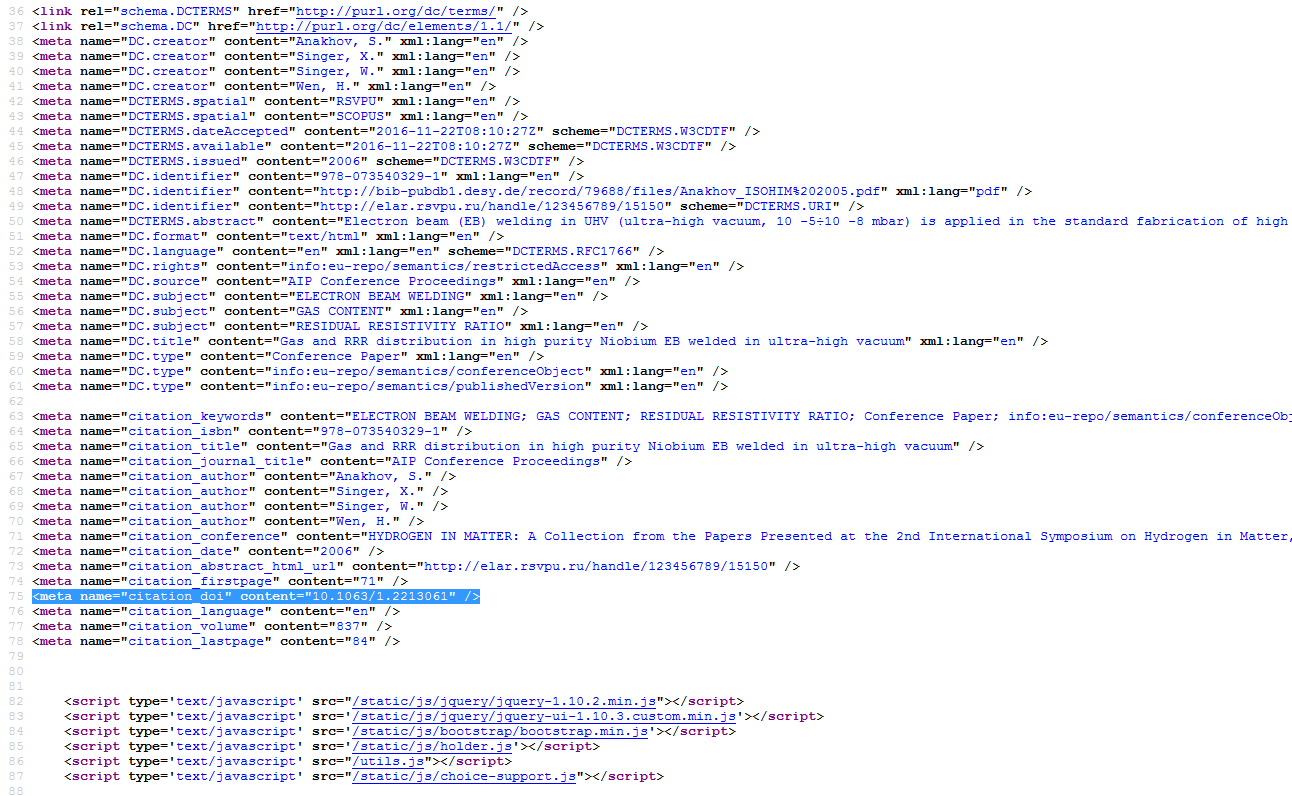
Т.е. видите метатег citation_doi, то установка плагина завершена. Если же такого тега нет, то необходимо во-первых убедиться в том, что поле для хранения DOI в репозитории есть и оно уникально для DOI (не подходит вариант хранения DOI в dc.subject, dc.identifier.other и пр. полях, могущих содержать значения, отличные от DOI!). Если такого поля нет, видимо, необходимо его ввести и заполнить. После этого, необходимо отредактировать файл google-metadata.properties, расположенный по пути /dspace/config/crosswalks/google-metadata.properties на предмет задания соответствия поля google.citation_doi введенному на предыдущем шаге полю.
Пример показан ниже:
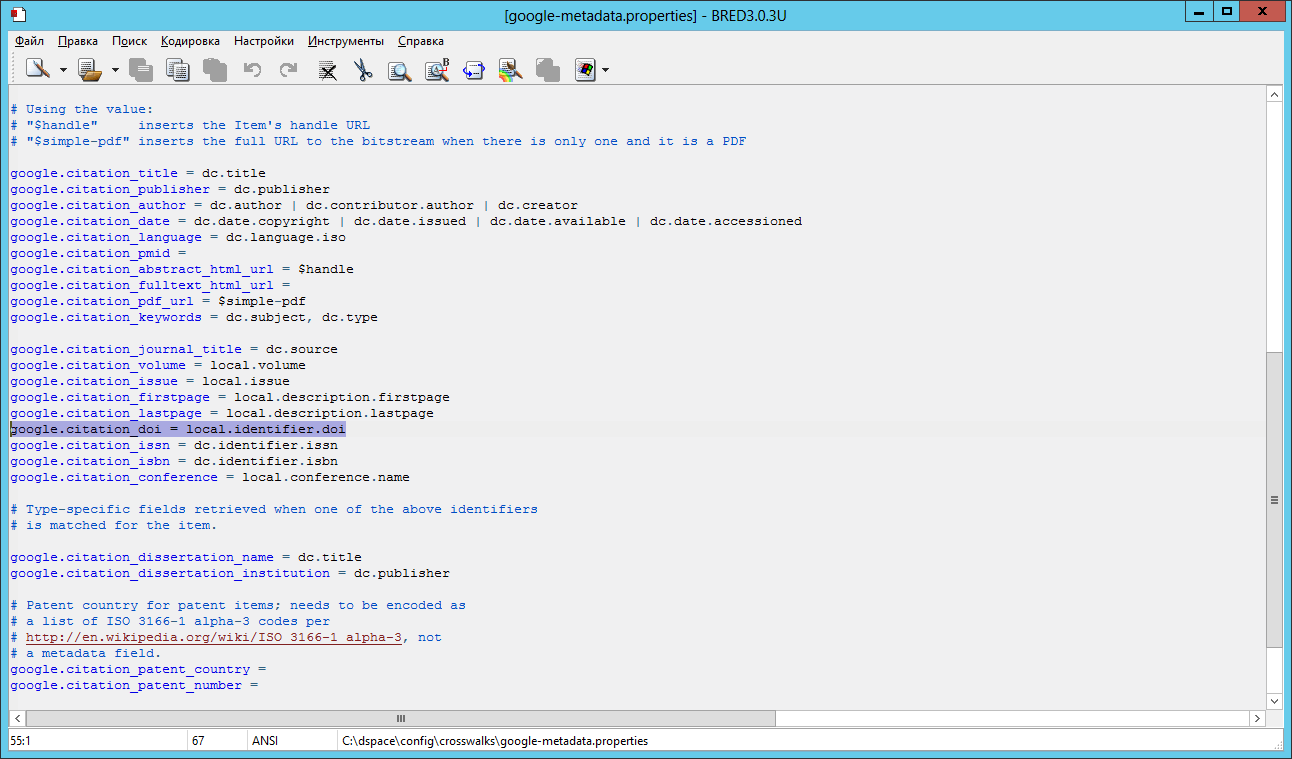
Отдельно хотелось бы отметить, что не достаточно просто отредактировать файл google-metadata.properties. Если в метаданных не будет значений DOI, либо они не будут верно передаваться в заголовке страницы, плагин не сможет подобрать полный текст из коллекции CORE.
Примеры работы плагина:
Хороший:
- Электронный архив РГППУ, русский язык
- Электронный архив РГППУ, английский язык
- Электронный научный архив УРФУ, русский язык
- Электронный научный архив УРФУ, английский язык
Плохой:
К сожалению, «плохих» (когда по ссылке CORE мы фактически имеем запрос оплаты или требование ввода логина и пароля) примеров не мало.
[UPD] Электронный научный архив УРФУ более не использует CORE Discovery. Плохой пример заключался в том, что вместо ссылки на полный текст, CORE возвращал ссылку на хендл документа в dspace — т.е. на ту же самую страницу.
Уведомление: Using CORE Discovery in DSpace – CORE